1、组播点播失败(通用故障)类故障的排查思路及信息收集
1)故障现象
组播网络部署完毕后,PC无法点播成功网络中心提供的组播视频
2)故障处理流程
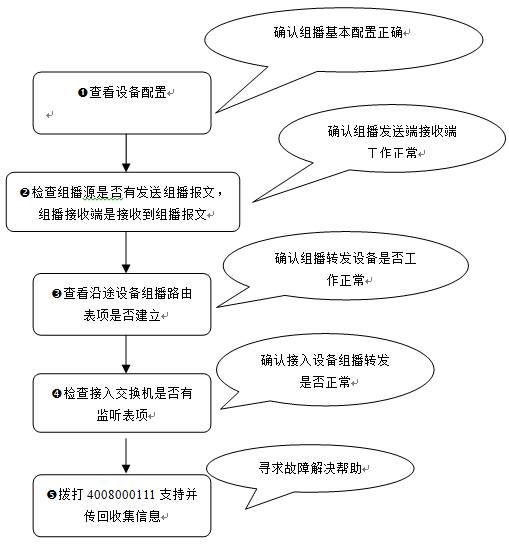
3)故障处理步骤
a.步骤1 配置检查
查看从组播源到接收者传输路径上的所有设备组播基本配置是否正确,目前常用的域内组播技术为PIM―DM和PIM-SM。
--》组播配置之前要求整个PIM域内单播路由已经部署完毕,各节点都路由可达。
PIM-DM基本配置检查:
是否全局开启组播路由协议(ip
multicast-routing);
是否在需要接受或转发组播的接口上都开启了PIM-DM和IGMP(默认开启组播路由的同时开启IGMP),特别是组播源以及用户端的SVI接口;
ruijie(config)#int vlan 10
ruijie(config-if-VLAN
10)#ip pim dense-mode
PIM-DM高级配置检查:
检查是否错误的配置了邻居过滤;
ruijie(config-if-VLAN 10)#ip pim
neighbor-filter DM-filter-ACL
优化过滤配置ACL是否配置错误导致合法组播/IGMP报文被丢弃
PIM-SM基本配置检查:
是否全局开启组播路由协议;
是否在需要接受或转发组播的接口上都开启了PIM-SM和IGMP(默认开启组播路由的同时开启IGMP);
配置静态RP或动态RP(C-RP与C-BSR);
ruijie(config)#ip
pim rp-address 1.1.1.1
PIM-SM高级配置检查:
检查是否配置了错误的邻居过滤;
配置的RP注册报文过滤是否正确;
ruijie(config)#ip
pim accept-register list 100
配置的BSR合法范围限制是否正确;
ruijie(config)#ip
pim accept-bsr list 200
配置的C-RP合法范围及组播组是否正确;
ruijie(config)#ip
pim accept-crp list 300
优化过滤配置ACL是否配置错误导致合法组播/IGMP报文被丢弃。
IGMP高级配置检查:
查看是否配置了IGMP
Access-Group 组播控制,是否添加ACL正确;
ruijie(config-if-VLAN
10)#ip igmp access-group 400
查看是否在一个有多用户的端口上错误的配置了fast-leave特性;
查看接口下配置的ip
igmp limit是否太小,缺省为1024.
接入交换机IGMP-Snooping配置检查:
Ruijie(config)# show ip igmp snooping
IGMP Snooping
running mode: SVGL
SVGL vlan: 1
SVGL profile
number: 11
Source port
check: Disable
Source ip check:
Disable
IGMP Fast-Leave:
Disable
IGMP Report
suppress: Disable
检查配置是IVGL模式或SVGL模式(SVGL必须配合IGMP Profile使用)
IGMP
Profile中只有在这批组播地址范围内的数据流,才可以是跨VLAN 转发,对于不在此范围内的组播流,将不能被转发;默认情况下所有的组范围都不在SVGL 的应用范围,所有的组播流将被丢弃
ip
igmp profile 11
permit
range 239.1.1.0 239.1.1.255
检查路由口是否静态配置或自动学习并开启了源端口/源IP检查(故障排查时可将源端口检查高级功能取消,防止相关高级安全功能干扰故障排查)
Ruijie(config)#ip
igmp snooping source-check port
检查用户端口是否开启IGMP
Snooping Fliter功能,可在故障排查时先取消。
b.步骤2 查看组播源是否有发出组播报文,组播接收端是否有接受到组播报文
在应用的层面查看组播源、组播接收端是否工作正常,可以考虑采用捉包的方式进行确认。在某些情况下可能存在组播源服务器部署错误、组播客户端参数设置错误等问题,可以在此步骤中进行排除或使用替换法解决;
同时对组播源的捉包有助于了解组播报文的特性,例如是否存在分片、组播报文大小、源目标IP,端口等、TTL等,通常了解这些参数对于后续的故障排查也是非常有用的。
c.步骤3 查看源途(从组播源到组播目标)设备是否有建立正确的组播路由表项
--》组播建立的前提:单播路由正常
PIM-DM的查看方法:
ruijie#show ip
mroute (转发表)
IP Multicast Routing Table
Flags: I -
Immediate Stat, T - Timed Stat, F - Forwarder installed
Timers:
Uptime/Stat Expiry
Interface State:
Interface (TTL)
组播源
组播目标
(210.34.130.27,
224.3.1.2), uptime 00:18:04 建立时间,
stat expires 00:01:21 超时时间
Owner PIMDM, Flags: TF
Incoming interface: TenGigabitEthernet
3/1 进入接口RPF接口
Outgoing
interface list: 出接口
TenGigabitEthernet 3/2 (1)
(210.34.130.27, 224.3.1.3), uptime 00:30:18, stat
expires 00:03:01
Owner PIMDM,
Flags: TF
Incoming
interface: TenGigabitEthernet 3/1
Outgoing interface list:
VLAN 125 (1)
VLAN 151 (1)
VLAN 123 (1)
VLAN 124 (1)
Ruijie# show ip pim dense-mode mroute(协议表)
PIM-DM Multicast Routing Table
(1.1.1.111,
229.1.1.1)
MRT lifetime
expires in 205 seconds
RPF Neighbor:
50.50.50.1, Nexthop: 50.50.50.1, VLAN 4
RPF检查
Upstream IF:
VLAN 4
Upstream State:
Pruned, PLT:200
Assert State:
NoInfo
Downstream IF
List:
FastEthernet
0/45:
Downstream
State: NoInfo
Assert State:
Loser, AT:170
上面的例子列出了(1.1.1.111,
229.1.1.1)的表项情况,其中MRT 老化时间为205 秒。RPF邻居为50.50.50.1,下一跳为50.50.50.1,到达下一跳的出口为VLAN4。表项的上游接口
为VLAN4,此时处于Pruned
状态,表示表项没有下游转发出口。下游接口有FastEthernet0/45,处于NoInfo 状态,并且接口的Assert 状态处于Loser,FastEthernet
0/45 不在转
发出口中。
重点关注1.表项是否建立 2. 入接口是否符合预期 3. 是否有转发接口
若表项未建立,需要进行排查:
PIM邻居是否正常show
ip pim dense-mode neighbor/show ip pim dense-mode interface/show ip mvif
PIM报文发送与接收是否正常(捉包或debug)
show ip pim dense-mode track/debug ip pim dense-mode all/各参数
PIM-SM的查看方法:
PIM存在2棵树,一个SPT为组播源到RP的路径,一棵树为RPT为组播目标到RP的树。
RPT树上节点的多播路由表和SPT上节点的多播路由表有所差别。由于RPT是可以许多源共享的一棵树,所以其协议路由表项为(*,G)模式(内部包含RP信息)。RP到源之间的SPT上的节点路由表项是(S,G)模式。RP上则同时有(*,G)[RPFnexthop为0.0.0.0]和(S,G)的表项。
ruijie#show ip
mroute(转发表)
(219.229.134.145, 239.202.0.5), uptime
00:09:14, stat expires 00:02:07
Owner PIMSM,
Flags: TFR
Incoming interface: VLAN 50
Outgoing interface list:
VLAN 25 (1)
VLAN 27 (1)
VLAN 30 (1)
VLAN 31 (1)
ruijie#show ip
pim sp mr(协议表)
IP Multicast
Routing Table
(*,*,RP)
Entries: 0
(*,G) Entries: 2
(S,G) Entries: 1
(S,G,rpt)
Entries: 1
FCR Entries: 0
REG Entries: 0
(*, 237.1.1.0)
RP: 192.16.57.48
RPF nbr:
0.0.0.0
//表明自己RP
RPF idx: None
Upstream State:
JOINED
(192.16.57.49,
237.1.1.0)
RPF nbr:
0.0.0.0 //表明自己是组播源DR
RPF idx: None
SPT bit: 1
Upstream State:
JOINED
kat expires in
48 seconds
(192.16.57.49,
237.1.1.0, rpt)
//根据(*,G)和(S,G)综合生成的表项
RP: 192.16.57.48
RPF nbr: 0.0.0.0
RPF idx: None
Upstream State:
NOT PRUNED
(S,G,rpt)用来表示 是否需要从rpt接收,
当rpt的入口和 spt的入口不一样的时候,进行spt切换会用到。
若协议表项未建立,需要进行排查:
PIM邻居是否正常show
ip pim sparse-mode neighbor [detail] show ip pim sparse-mode interface/show ip
mvif
查看是否有RP映射show
ip pim sparse-mode rp mapping
查看BSR信息show
ip pim sparse-mode bsr-router
PIM报文发送与接收及处理机制是否正常(捉包或debug)show
ip pim sparse-mode track/debug ip pim sparse-mode(众多选项,例如packets/event/state/nsm/mfc/all)
ip mroute表项建立后,转发异常,可进行如下排查
Show
msf msc
debug
msf 获取信息
clear
ip mroute 重新观察表项生成情况
d.步骤4 查看接入交换机IGMP-Snooping表项是否建立
IGMP Snooping可以从有效抑制组播数据在二层网络中的扩散,当不使用IGMP
Snooping功能时,组播被当做广播在VLAN内进行转发,当使用IGMP Snooping时,则只有有点播需求的用户端口才会收到相应的数据。如果不配置SNP功能组播正常,使用SNP后组播故障,则需重点排查SNP表项生成的问题。
查看表项
Ruijie#show ip igmp snooping gda-table
Multicast Switching Cache Table
D:
DYNAMIC
S:
STATIC
M: MROUTE
(*, 224.1.1.1,
100):
VLAN(100)
2 OPORTS:
GigabitEthernet 0/13(M)
GigabitEthernet 0/22(D)
若表项未建立,需要进行排查:
网关上show
ip igmp group,debug ip igmp events或捉包查看IGMP报文收发情况;
客户端pc上捉包查看igmp报文收发情况;
接入交换机上执行debug
igmp-snp event和debug igmp-snp packets (debug igmp-snp msf可选)
e.步骤5 如经过以上排查依然无法定位原因。请收集如下信息并提交到4008-111-000
客户组播应用模型;
设备配置;
设备上的组播表项show的相关信息;
按照以上1-4步骤排查的相关debug信息;
按照以上1-4步骤排查相关的捉包数据。
2、部署三层组播(PIM)后设备CPU100%的故障排查思路及信息收集
1)故障现象
S86 CPU利用率100%,查看进程发现nsmd进程CPU利用率非常高,客户全网启用了PIM-DM协议。
如果nsmd线程的cpu过高,可能是这个功能有大量的处理逻辑;可能是大量的末知名组播数据报文送上来需要处理;组播核心需要通告给PIM模块导致的;可能是大量的IGMP协议报文送上来需要处理。
ruijie#show cpu
=======================================
CPU Using Rate
Information
CPU utilization
in five seconds: 100%
CPU utilization
in one minute : 100%
CPU utilization
in five minutes: 61%
NO 5Sec 1Min 5Min Process
53 87% 90% 49% nsmd
107 2% 2% 2% ssp_flow_rx_task
131 0% 0% 39% idle
//此处只列出主要线程
查看设备CPU报文接收情况,发现组播相关的报文量都很大
ruijie# show
cpu-protect mboard
Type
Pps
Total Drop
------------------- --------- ---------
---------
tp-guard
0
0
0
arp
31
453692 0
dot1x
0
0
0
rldp
0
0
0
rerp
0
0
0
reup
0
0
0
slow-packet
0
0
0
bpdu
6
60170
0
isis
0
0
0
dhcps
0
0
0
gvrp
0
0
0
ripng
0
0
0
dvmrp
0
0
0
igmp
2
191623
13052 IGMP丢弃,说明曾经IGMP
PPS很大
mpls
0
0
0
ospf
0
3410
0
ospf3
0
2537
0
pim
40
276920
12968 PIM协议报文
pimv6
0
0
0
rip
0
0
0
vrrp
0
0
0
mld
0
0
0
unknown-ipmc
7
28159
8 未知组播,表示未建立表项的组播报文
unknown-ipmcv6 0
0
0
stargv-ipmc
0
0
0
bgp_ttl1
0
0
0
ttl1
0
15399
2
hop_limit1
0
219
0
ttl0
0
0
0
dhcp-relay-c
7
76398
0
dhcp-relay-s
0
0
0
option82
0
0
0
udp-helper
0
0
0
tunnel-bpdu
0
0
0
tunnel-gvrp
0
0
0
ip4-packet-local 49
410762 0 目标IP是本地的报文
ip6-packet-local 1
5607 0
ip4-packet-other 200
2064530 722542 目标IP非本地,但需要CPU处理的(非以上详细分类)
ip6-packet-other 0
1462
0
ipv6mc
5
108763 1682
non-ip-packet-other 0
0
0
2)故障处理流程
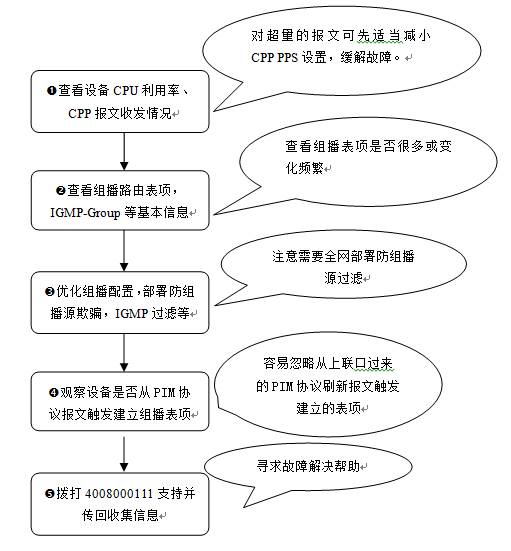
3)故障处理步骤
a.步骤1
对于CPU利用率高的问题,常规信息收集手段包括:
1)查看CPU进程,查看CPP报文收发情况,show
cpu,show cpu-protect mboard;
2)当设备可以管理(包括telnet或Console)的时候,进入debug
support模式,执行show task 3-5次,show tech-support 2次;
3)当设备Console口也无法管理的时候,可先获取1次@@@@@,多次执行@@@@T,@@@@M,@@@@S继续执行一次@@@@@
针对组播导致设备CPU利用率高的问题,原因一般在于以下两个方面:
1)众多PIM、IGMP报文、未知组播送交换机都需要CPU进行处理导致的CPU利用率高。
2)锐捷的组播在表项超过硬件容量后,超出的部分能够基于软件转发,超过硬件容量的报文走CPU转发导致CPU利用率高(show msf
msc确认)。
本案例中对于IPV4 other的报文可先行减小CPP阈值,查看是否能够缓解一定的CPU利用率
Ruijie#show cpu-protect summary
Type
Pps
Pri
------------------- --------- ---------
ip4-packet-other 200 0 //默认ip4-packet-other的优先级为0,限速阀值200pps
ip6-packet-other 200 0
Ruijie(config)#cpu-protect
type ip4-packet-other pps 50
//调整为50pps
b.步骤2
查看组播路由表项,发现存在大量用户网段为源的组播表项
ruijie#show ip
mroute
(172.22.150.134, 224.112.56.29), 00:19:35/00:02:50,
PIMDM, Flags: TF
(172.22.150.140,
224.112.56.29), 00:40:20/00:02:50, PIMDM, Flags: TF
(172.22.150.154, 224.112.56.29), 00:39:20/00:02:50,
PIMDM, Flags: TF
(172.22.150.177,
224.112.56.29), 00:03:53/00:02:50, PIMDM, Flags: TF
(172.22.150.188, 224.112.56.29), 00:08:39/00:01:10,
PIMDM, Flags: TF
(172.22.150.200,
224.112.56.29), 00:03:34/00:01:10, PIMDM, Flags: TF
(172.22.150.206, 224.112.56.29), 00:01:45/00:02:50,
PIMDM, Flags: TF
(172.22.150.208,
224.112.56.29), 00:39:12/00:02:50, PIMDM, Flags: TF
(172.22.151.12, 224.112.56.29), 00:35:19/00:02:50,
PIMDM, Flags: TF
(172.22.151.23,
224.112.56.29), 00:39:44/00:02:50, PIMDM, Flags: TF
(172.22.151.24, 224.112.56.29), 00:11:54/00:02:50,
PIMDM, Flags: TF
(172.22.151.35,
224.112.56.29), 00:11:56/00:02:50, PIMDM, Flags: TF
(172.22.151.36, 224.112.56.29), 00:01:31/00:01:59,
PIMDM, Flags: TF
(172.22.151.37,
224.112.56.29), 00:02:52/00:02:50, PIMDM, Flags: TF
(172.22.151.42, 224.112.56.29), 00:15:23/00:02:50,
PIMDM, Flags: TF
(172.22.151.45,
224.112.56.29), 00:08:15/00:01:10, PIMDM, Flags: TF
(172.22.151.51, 224.112.56.29), 00:21:48/00:01:10,
PIMDM, Flags: TF
(172.22.151.58,
224.112.56.29), 00:39:39/00:02:50, PIMDM, Flags: TF
(172.22.151.67, 224.112.56.29), 00:35:18/00:02:50,
PIMDM, Flags: TF
(172.22.151.68,
224.112.56.29), 00:08:41/00:02:50, PIMDM, Flags: TF
(172.22.151.72, 224.112.56.29), 00:05:53/00:02:50,
PIMDM, Flags: TF
注:Windows主机默认支持Upnp(即插即用特性),会发出目标为239.255.255.250的组播包,导致设备建立众多组播路由表,可能导致设备组播路由表溢出。
查看IGMP Group发现建立了大量非合法的组播组
ruijie#show ip
igmp groups
239.255.255.239 VLAN 127
00:00:02 00:04:17 58.199.24.77
239.255.255.250 VLAN 127 03:49:23 00:04:15 58.199.24.115
224.1.1.1 VLAN
131
00:02:02 00:02:17 58.199.28.85
224.112.56.29 VLAN 131
00:00:03 00:04:16 58.199.28.48
239.255.255.239 VLAN 131
00:02:07 00:04:18 58.199.28.87
239.255.255.250 VLAN 131
00:02:10 00:04:15 58.199.28.32
224.112.56.29 VLAN 121
00:04:14 00:00:05 58.199.18.46
239.255.255.250 VLAN 121
00:08:24 00:04:15 58.199.18.57
224.3.1.3 VLAN
103
00:02:05 00:04:17 58.199.1.64
224.112.56.29 VLAN 103
00:02:09 00:04:14 58.199.1.26
239.255.255.239 VLAN 103
00:00:05 00:04:15 58.199.1.91
239.255.255.250 VLAN 103
00:02:09 00:04:14 58.199.1.20
本案例中需要进行组播网络全网优化:包括但不限于组播源控制(只允许合法的组播源)、IGMP组过滤(只允许提供的合法组播组)、接入组播监听及profile过滤,配置可参考常见咨询中的示例。
c.步骤3
观察设备是否从PIM协议报文触发建立组播表项
在实际部署组播中,对于设备下游所设置的防组播源欺骗,确实可以过滤欺骗从下游产生,但我们通常容易忽略一个问题,就是通过上游接口PIM-DM协议报文导致的设备频繁建立组播表项的问题。PIM-DM的状态刷新泛洪机制,连接组播源的DR设备接收到组播报文,也会创建组播路由,并且封装成pimv2的状态刷新报文分发给下游,会导致下游设备刷新建立表项,下游无用户加入时才会进行剪枝操作,可以避免周期性的流Flood行为,较少网络拥塞的可能性。这种机制设计本身是优化组播频繁周期性的组播流Flood行为的,但如果源DR也遭受了组播源欺骗,那么其PIM
State Refresh就会将众多的组播表项信息发送给下游,导致出现问题。所以我们通常要求组播优化需要全网进行,否则仍然有可能遇到由于PIM协议扩散导致的路由表溢出问题。
该步骤可以在组播源所在的那台三层设备做抓包确认,或者是show
ip mroute,show ip igmp groups,show msf msc
d.步骤4
在经过以上步骤排查仍然未能解决问题,则可以拨打4008111000获取支持,收集以下信息连同前面的操作信息一同反馈给工程师处理。
客户组播应用模型
设备配置
设备上的组播表项
按照以上1-3步骤排查的相关信息
按照以上1-3步骤排查相关的捉包数据
3、用户点播组播视频卡故障类排查思路及信息收集
1)故障现象
S26做组播环境测试,测试环境较为简单:组播源―S86―S57―千兆―S26―百兆―PC,用户网关在57上,S26的配置仅开启了组播监听,风暴控制关闭,组播会出现马赛克现象,但看CCTV1视频不卡,看CCTV5才会卡。
设备配置如下:
interface
FastEthernet 0/1
switchport access vlan 18
no storm-control broadcast
no storm-control unicast
spanning-tree bpduguard enable
spanning-tree portfast
interface
GigabitEthernet 0/25
switchport mode trunk
medium-type fiber
spanning-tree bpdufilter enable
ip igmp profile
1
permit
range 239.251.192.0 239.251.207.255
!
ip igmp snooping
ivgl
ip igmp snooping
vlan 18 mrouter interface GigabitEthernet 0/25
ip igmp snooping
suppression enable
2)故障处理流程
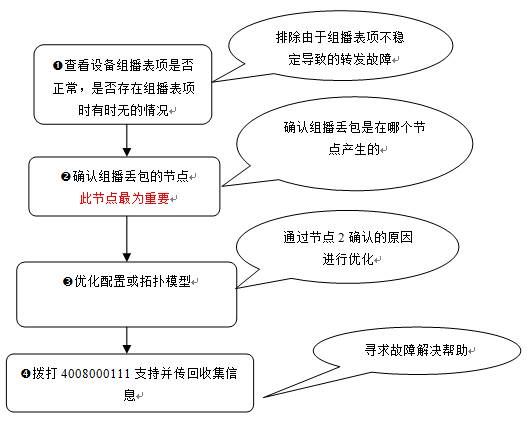
a.步骤1 查看设备组播表项是否正常,是否存在组播表项时有时无的情况
组播表项是否正常是组播能否正常转发的前提,当组播表项反复添加删除的时候则可能会导致组播转发断流。
三层设备:show ip
mroute,show ip pim dense-mode/spare-mode mroute;二层设备:show ip igmp snooping
gda-table,查看点播的组是否存在频繁变化。
组播表项的增删通常是由于收到了剪枝报文、用户离开组、表项老化时间的到达导致,可重点关注。
三层设备:debug ip
pim dense-mode all,debug ip pim sparse-mode events/packet;二层设备:debug igmp-snp
events/packet
b.步骤2 确认丢包的节点
确认丢包的方法通常有如下思考和处理方式:
在设备的不同层次上接PC进行测试,查看在哪个层次的设备上即已经发生了丢包。
查看端口计数确认是否有nobuffer丢帧或HOL溢出,并且存在增长。
show
interface counter,show interface
在PC上捉包,确认报文接受是否和发送的报文一致,部分情况下可能由于服务器发包异常或PC端软件问题导致
使用替换法进行设备替换测试
以上方法需要根据实际情况灵活使用。
c.步骤3
在经过以上步骤排查仍然未能解决问题,则可以拨打4008111000获取支持,收集以下信息连同前面的操作信息一同反馈给工程师处理。
客户组播应用模型
设备配置
设备上的组播表项
按照以上1-2步骤排查的相关信息
按照以上1-2步骤排查相关的捉包数据
3)本次故障解析:
a.组播丢包先确认组播表项是否正常,是全局问题还是单个PC的问题。如担心组播表项异常(例如老化更新),可创建静态表项。
b.判定是节目问题还是设备问题导致的马赛克现象,为确定组播丢包在哪里,现场可将PC直接接入S57,查看是否出现马赛克,结果S57接入看CCTV1、5均不会出现马赛克,初步判断跟节目源没有太大关系。
c.那么可以确定在S26上发生了丢包了,进一步查看上层端口计数发现一切正常。需要进入底层进行查看,可以对比发现看CCTV1不卡的时候,底层没有HOL计数,但看CCTV5的时候,底层出现了较多HOL溢出。(关于SD的使用请联系4008中心支持)
S26-Test(sd)#sh show cou
RUC.ge4 :
628,352
+130,128 519/s
RDBGC0.ge4
: 877,970 +180,898 700/s
RUC.fe1 : 2,071
+377 2/s
RDBGC1.fe1
:
65 +9
HOLD.fe1 : 5,604
+1,975 15/s 每秒有15个包被丢弃。
GRMCA.fe1 : 65 +9
GRBCA.fe1 : 130 +1
以上信息能够充分证明,视频马赛克正是由于HOL溢出所致。现场环境中,千兆口为Ingress口,百兆口为Egress口,根据我们之前分析的HOL溢出的可能性即为此千兆口向百兆口发包速率太快所致。
为了证明由于此原因所致,我们将26与57互联的端口打开流控(接口下配置flow-control
on),马上恢复正常,并在PC上同时点播3个节目,都不会出现卡的现象。因为在pause帧的作用下,57这边发包速率会降低,最终不会发生HOL阻塞的现象。 同时,我们还做了另外一个测试,将26与S57的接口修改为100M,那么S57的发包速率也降低了,且26上成为100M口接口向100M接口发包,26上的用户也不会出现马赛克的现象
4)分析为什么CCTV5视频会导致HOL溢出,但CCTV1视频却不会?而且视频码流大概为3Mb/s即可满足组播视频的效果。为何百兆口还会发生HOL拥塞?
我们使用仪表模拟组播报文的转发情况,在千兆口使用仪表发送100Mb/s的组播流,百兆口接受,但底层调试的结果,也没有发现出现HOL的情况。从交换机的缓冲区设计来说,也足以满足百兆端口百兆转发的性能需求。为何现场会出现“3Mb/s”的组播情况下,依然会出现组播丢包的情况?
因为我们所讲的100Mb/s为平均速率,但如果组播流的猝发速率超出了交换机所能承受的范围,一样会导致底层出现HOL丢包。我们继续使用仪表进行了模拟测试,在千兆口发送猝发报文,猝发速率达到300Mb/s的时候,由于百兆出口不能够承受300Mb/s的猝发速率,导致HOL阻塞,底层的HOL溢出已经非常严重了。3Mb/s所指只是视频源码流的速率,由编码器发出的时候,有些编码器的编码可能是变码,部分可能会定码,所以最终组播视频流的发送速率也并不一致,在实际网络中传输的时候由于中间设备的缓冲、发送功能也会导致数据发送速率根据接口的速率相应发生变化。而且在现场测试环境中,26和57之间的接口为trunk口,也会接受到其他一些数据流,导致超出了接口出队列,产生了HOL溢出。这也就是出现CCTV1不卡,而CCTV5卡的原因所在。
4、S86提示*Nov 30
08:30:27: %7: IPv4 Multicast route limit 1024 exceeded,该如何处理
S86的组播硬件表项为1K,当上层软件组播表项超过1024后,系统就会提示该消息。
可以通过show ip
mroute,show ip igmp groups来确认表项数量
建议优化组播路由表项,具体案例参考常见咨询的优化章节
如果设备直连大量微软客户端,建议通过ACL直接过滤微软upup组播源地址。
注:Windows主机默认支持Upnp(即插即用特性),会发出目标为239.255.255.250的组播包,导致设备建立众多组播路由表,可能导致设备组播路由表溢出。